
Con la oportunidad de presentar información censal relevante que agrupe tanto población afrodescendiente como indígena en la base de datos de la División de Estadística de la Cepal (CEPALSTAT), surge el Sistema de Indicadores Sociodemográficos de Población y Pueblos Indígenas y Afrodescendientes - SISPPIA el cual presenta información para 171 países de la región, los que abarcan las rondas censales de 2000, 2010 y 2020.
El objetivo general del SISPPIA es difundir una herramienta de apoyo a la toma de decisiones de políticas públicas orientadas a disminuir las inequidades étnico-raciales y fomentar el desarrollo de los pueblos indígenas y de los afrodescendientes. El SISPPIA incluye indicadores sociodemográficos seleccionados, que permiten identificar brechas étnico-raciales, generacionales y por sexo, en base a los censos de población y vivienda. Estos indicadores han sido calculados con procesamientos especiales de los microdatos censales disponibles en el CELADE, utilizando Redatam. El procesamiento implicó diferentes etapas: la identificación de variables pertinentes, la homologación de las mismas a partir de la creación de nuevas variables o la recategorización de las originales, el diseño de los indicadores y su obtención y validación final.
Acorde los requerimientos de CEPALSTAT, para cada indicador del SISPPIA se construyó una nota técnica que incluye la definición conceptual, unidad de medida, metodología de cálculo, fuentes, desagregaciones y consideraciones especiales. Asimismo, y de manera específica al SISPPIA, se elaboró un documento con las definiciones operacionales relacionadas con la identificación étnico-racial de cada uno de los países cuyos censos se procesaron.
En el proceso de definir la “arquitectura” de SISPPIA se crean dos áreas con sus respectivos indicadores considerados relevantes. De esta forma se genera una estructura que agrupa una serie de indicadores en las áreas de Población y Sociales, a saber:
| Población | Sociales |
|
Población indígena y no indígena según área de residencia |
Asistencia escolar de la población de 6 a 11 años que asiste a algún establecimiento educativo según condición étnico-racial por sexo y área de residencia. |
|
Población afrodescendiente y no afrodescendiente según área de residencia |
Asistencia escolar de la población de 12 a 17 años según condición étnico-racial por sexo y área de residencia. |
|
Porcentaje de población afrodescendiente por área de residencia. |
Asistencia escolar de la población de 18 a 22 años según condición étnico-racial por sexo y área de residencia. |
|
Estructura de la población indígena según edad y sexo, por área de residencia. |
Porcentaje de jóvenes de 20 a 24 años que concluyó la secundaria según condición étnico-racial y sexo. |
|
Estructura de la población afrodescendiente según edad y sexo, por área de residencia. |
Tasa de participación económica de la población de 15 años y más según condición étnico-racial por edad, sexo y área de residencia. |
|
Índice de masculinidad según condición étnico-racial por edad y zona de residencia. |
Tasa de desempleo de la población de 15 años y más según condición étnico-racial por edad, sexo y área de residencia. |
|
Relación de dependencia según condición étnico racial, por edad y zona de residencia. |
Porcentaje de personas en hogares sin servicio de agua potable según condición étnico-racial, por área de residencia. |
|
Porcentaje de población urbana según condición étnico-racial, por edad y sexo. |
Porcentaje de personas en hogares sin servicio de saneamiento según condición étnico-racial, por área de residencia. |
|
Porcentaje de mujeres de 15 a 19 años que han tenido hijos nacidos vivos, según condición étnico-racial, por edad. |
Población en situación de pobreza extrema y pobreza según etnia, sexo y área geográfica. |
De forma simultánea se procede a realizar dos procesos de generación de variables:
a) Generar la variable básica de pueblo (afrodescendiente, indígena y resto), las cuales utilizaremos para todos los cruces e indicadores a realizar.
Como se puede observar en el siguiente cuadro, en donde se presenta la programación para crear la variable básica, se recodifica una variable de acuerdo con la definición del país. Este es un ejemplo sencillo de programación. En algunos países, tomar una decisión para agrupar a las personas afro indígenas requiere de un análisis más detallado.

b) Al mismo tiempo se generan las variables que caracterizan a la población, y que no existen como tal para este sistema. Por lo tanto, deben crearse con Redatam. En algunos casos, variables como sexo y edad también es necesario recodificarlas para poder generar programas genéricos que posibiliten una salida de datos estandarizada, que luego permita a través de pocos comandos, obtener grandes volúmenes de información que alimenten CEPALSTAT. Es importante recordar que se trabaja con bases de 17 países y por ello se necesita ser lo más eficientes posibles. Una variable que requiere un mayor detalle en su creación es la de la población económicamente activa, en este caso la “complicación” radica en que debemos utilizar filtros que remiten a otras variables, como la edad. Este problema se soluciona con el comando switch, el que permite combinar distintas variables para construir otras. De esta manera, asegura que la población solamente tenga determinadas edades, de manera consistente a la pregunta de población en edad de trabajar (PET).

Una vez realizado este trabajo para todas las variables intervinientes, y estandarizado los nombres de las variables y las categorías necesarias, el siguiente paso corresponde a generar los indicadores que se deben cargar en CEPALSTAT.
En este caso se usan las variables anteriormente creadas y estandarizadas para calcular e indicador de “asistencia escolar de la población de 6 a 11 años que asiste a un establecimiento educativo según condición étnico racial por sexo y área de residencia”

ii Esta sintaxis nos permite ir agregando las tablas de resultados según criterio a un mismo a archivo, en este caso el criterio es país, censo, año e indicador.
iii Al construir un estilo de tablas estandarizamos la salida de resultados utilizando la misma para cada indicador.
Como se observa en la programación anterior se crea una tabla que corresponde a un cruce de variables que asisten a la escuela entre 6 y 11 años, dividida usando el comando tabop, por la tabla del total de personas entre 6 y 11 años multiplicado por 100. A continuación, un cuadro de resultados del cruce de asistencia por área y condición étnica para el censo de Argentina 2010. Estos resultados en Excel nos sirven para mantener el control de la información que vamos a obtener.
Asistencia a la escuela entre 6 y 11 años por área de residencia, sexo y condición étnico-racial. Argentina 2010
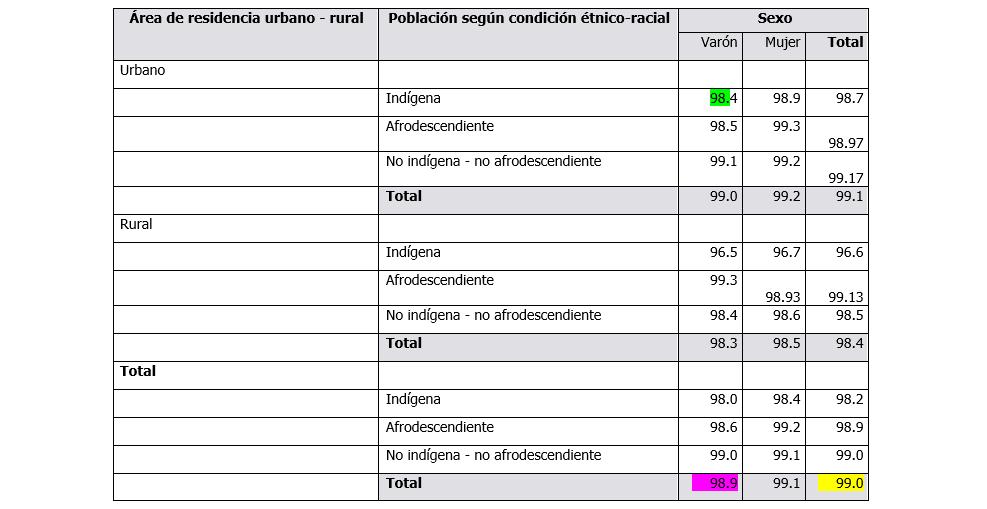
Fuente: Procesado con REDATAM.
Hasta aquí la programación de variables y uso de comandos cumple con lo que regularmente hacemos en Redatam cuando se obtiene un indicador. Sin embargo, existe la posibilidad de obtener esta misma información en otro tipo de salida llamado SIDRA2, que es la que nos permite obtener una gran cantidad de datos en un formato estandarizado.

V “Existen casos donde los indicadores requieren menos filtros que otros, por tanto, en el cruce esas dimensiones no se evalúan; no obstante, como ya se aclaró, el formato SIDRA debe mantener el mismo orden de las dimensiones para la salida. En estos casos, existe el parámetro suplente S= que permite asignar un valor en la posición de la dimensión no evaluada, manteniendo el orden de la tabla de salida.” (Para más información ir a la ayuda de Redatam).
Para estandarizar las salidas del indicador procesado (porcentaje de asistencia escolar de la población de 6 a 11 años), en el formato SIDRA, en este caso se multiplica al resultado previamente obtenido por 1.
Como se observa (destacado en amarillo) la salida que obtendremos es en txt, cada celda de la tabla que usamos es una línea del archivo. Lo que se hace en sidraparm es definir los parámetros que se necesitan, algunos de ellos son informativos, por ejemplo:
T=%PA% corresponde al país;
>A=%AN% corresponde al año de la base censal;
V=%IND% al número asignado al indicador;
D=4 es la cantidad de decimales presentes en la salida;
N=1 corresponde al nivel geográfico
O=0 fuente de datos
C0, C1, C2, etc, corresponden a las dimensiones del cruce en este caso área, pueblo y asistencia, por lo tanto, es la información para cargar en SISPPIA.
A continuación, un extracto de los resultados de salida de Argentina censo del 2010 luego de procesar la información parametrizada. Como se puede observar y de modo practico los colores asignados también se encuentran en la tabla Excel a modo de ejemplo de cómo se obtiene la información.
Extracto de los resultados de salida del indicador en formato ASCII. Argentina 2010

Como aún es necesario algunas referencias externas como notas y fuentes (creadas en CEPALSTAT) externas al trabajo en Redatam, la carga final de la información se realiza pasando los datos a un formato tipo valores separados por coma .csv, que permite un manejo más rápido para poner estas referencias. Una vez generado este archivo es transferido a la plataforma CEPALSTAT en donde ya se generó un nodo con el tema y subtema específico al indicador para que los usuarios puedan acceder a él.
Población indígena y no indígena, según área de residencia
(miles de personas)
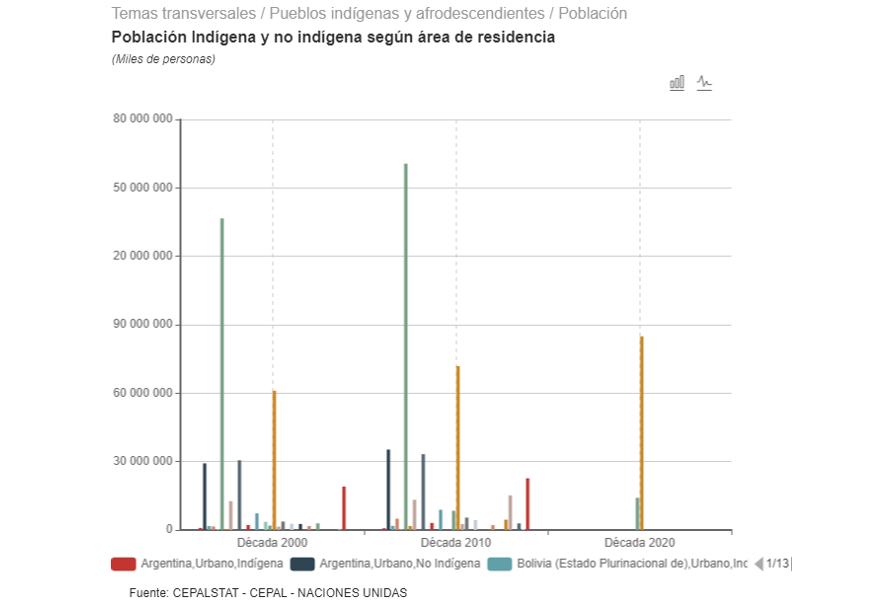
Fuente: CEPALSTAT.
En CEPALSTAT los indicadores de SISPPIA se pueden adecuar a los requerimientos del usuario en donde se posibilita elegir diferentes filtros, los cuales ya son parte del indicador y fueron previamente calculados en Redatam según se menciona más arriba.
A la fecha, el SISPPIA incluye 19 indicadores desagregados por diferentes variables, que posibilitan una primera e importante aproximación a la situación sociodemográfica de los pueblos indígenas y de los afrodescendientes de AL, y que se complementará a futuro con indicadores complementarios. Con ello se promueve la producción de información y de conocimiento actualizado sobre sobre estas poblaciones, como parte de las actividades prioritarias del CELADE, División de Población de la CEPAL. En particular, la desagregación de datos por grupos étnicos-raciales forma parte de los compromisos de la Agenda 2030 para el Desarrollo Sostenible (2015), como así también del Consenso de Montevideo sobre Población y Desarrollo (2013).
___________________________________________________________________________
1 Argentina, Bolivia (Estado Plurinacional de), Brasil, Chile, Colombia, Costa Rica, Cuba, Ecuador, El Salvador, Guatemala, Honduras, México, Nicaragua, Panamá, Paraguay, Uruguay, Venezuela (República Bolivariana de).
2 “SIDRA, como formato de tabla de salida ASCII, viene con una serie de campos que permiten ser llenados por las variables relacionadas. El punto clave en este tipo de programación es que el orden de las dimensiones (variables) es exactamente el mismo orden que presentará la tabla de salida final”