El presente artículo tiene la finalidad de exponer, brevemente, una síntesis de los pasos para la obtención de estas bases consolidadas, entregando una serie de lineamientos que permiten la actualización de dichas bases en el tiempo, de acuerdo con la disponibilidad continua de estos datos, así como sus desafíos y oportunidades, ya que, dicho proceso se puede aplicar a otro conjunto de datos seriales como encuestas de hogares, de trabajo, de educación, etc.
Fuente de los datos
Para contar con una base consolidada de hechos vitales es relevante mencionar su fuente. Se hace referencia a los registros administrativos de los hechos vitales, a aquellos datos de nacimientos y defunciones, en sus diferentes áreas, que son captados de forma periódica y constante, en las diferentes instituciones oficiales de los países y que son, además de la información propia que entregan, insumos para el cálculo de indicadores que permiten comprender nuestras poblaciones, y planificar los diferentes programas para el desarrollo de nuestros países.
Diagnóstico de acceso
El inicio del proceso de armonización y consolidación de datos empieza con el diagnóstico de los diferentes tipos de acceso a los microdatos de hechos vitales para cada uno de los países. Por esto, se hace una revisión de la disponibilidad de la información a través de los portales institucionales del registro civil, ministerio de salud y/o institutos de estadística de cada uno de los países.
En este proceso se identificaron dos tipos de acceso: primero, por descarga directa y pública desde las distintas páginas web, y la segunda, a través de solicitudes formales, por parte del CELADE - División de Población de la CEPAL, a las oficinas correspondientes, debido a que los microdatos no están disponibles para uso público. Asimismo, es relevante destacar que la disponibilidad de microdatos se presenta de distintas formas, ya sean con bases mensuales, anualizadas o consolidadas (serie de años).
En el cuadro siguiente se encuentra un resumen de la disponibilidad, por tipo de acceso, para los países de la región:
Cuadro 1: Disponibilidad por tipo de acceso
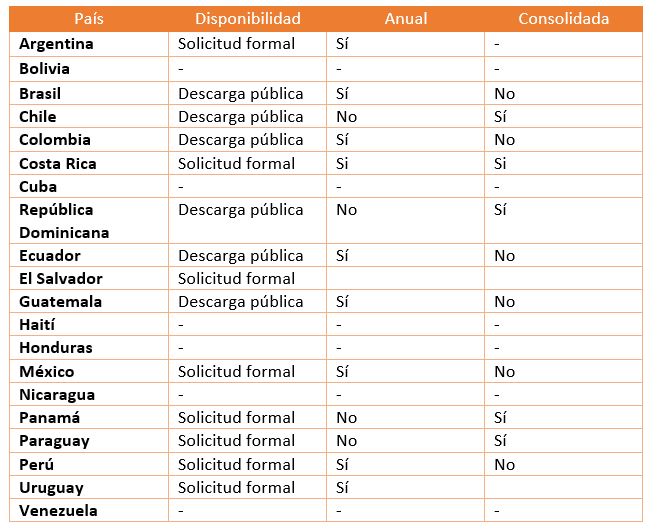
Fuente: Elaboración propia.
Revisión preliminar de las bases y sus formatos
Una vez elaborado el diagnóstico, y obtenidas las bases, se procede a la revisión de estos. Algunos de los tipos de archivos disponibles para las bases son Redatam, CSV, DBF, SPSS Statistics (*.sav), entre otros. También es importante mencionar en esta revisión preliminar, realizar la revisión de la periodicidad de estos datos, ya que de ello depende los pasos siguientes para la armonización.
En el cuadro siguiente se encuentra un resumen por país, de los formatos de los archivos:
Cuadro 2: Formatos de archivos utilizados por país
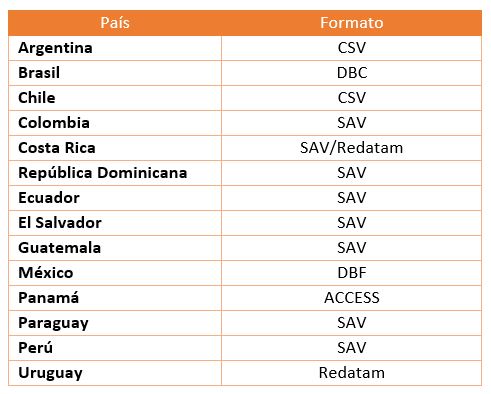
Fuente: Elaboración propia.
Al tener una importante variedad de formatos, se entiende que existen varios procesos, algunos más complejos que otros, para lograr la armonización entre bases. La mayoría de los datos requieren un pre-proceso para su adaptación al formato Redatam, y a veces, incluso las mismas bases que vienen en dicho formato deben ser revisadas y estandarizadas, ya que no vendrán en el formato deseado, por lo cual es necesario realizar algunas modificaciones se hacen algunas gestiones adicionales para obtenerlas de esa forma. Un ejemplo de esta situación fue el caso de los microdatos de Uruguay, quienes manejan su información en una aplicación de procesamiento en línea con Redatam Webserver (http://colo1.msp.gub.uy/redbin/RpWebEngine.exe/Portal) pero tenían una estructura jerárquica diferente al formato planteado, por lo cual se solicitó el apoyo a la institución responsable, para que los datos fueran ajustados a la estructura deseada antes de poder trabajarlos.
Definición de estructura base de datos en Redatam
Para crear bases de datos en formato Redatam es necesario definir, previamente, una estructura jerárquica que permita la relación entre los datos; haciendo necesarias las actividades de diagnóstico y revisión antes mencionadas, para así identificar las variables que serán los códigos identificadores en esta jerarquía, o bien, crear dichos campos faltantes para la jerarquía común a utilizar.
Cabe destacar que, la jerarquía definida en este apartado permite no solo unir las bases de nacimientos y defunciones en una sola base por país; sino que, adicionalmente, permitiría en un futuro, la unión de todos los países, independientemente de sus características particulares, en una sola base común de la región, con la mayor cantidad de variables factibles de homologar.
Una vez revisadas las bases, se establecieron las siguientes entidades y códigos de entidades para todas las bases a construir:
Cuadro 3:Entidades definidas para la base de datos

Fuente: Elaboración propia.
Es así como, se procede a crear las jerarquías comunes para cada hecho vital (nacimientos y defunciones), por país, que luego serán unidas en una base consolidada de hechos vitales. Las mismas quedaron de la siguiente manera:

Lineamientos para la armonización de datos
Para la sistematización, y posterior armonización, se debe realizar un trabajo exhaustivo en todas las variables disponibles de las bases, prestando especial atención en la revisión de los nombres de los campos y su contenido, para evitar duplicación de información, debido a que existen leves modificaciones del nombre de estos a través del tiempo.
Un ejemplo de ello es el caso de Ecuador, que, para la unidad geográfica “Cantón” y para la variable asociada a la temporalidad “Años”, entre otros, existen diferencias de formato entre las distintas series, como se visualiza a continuación:

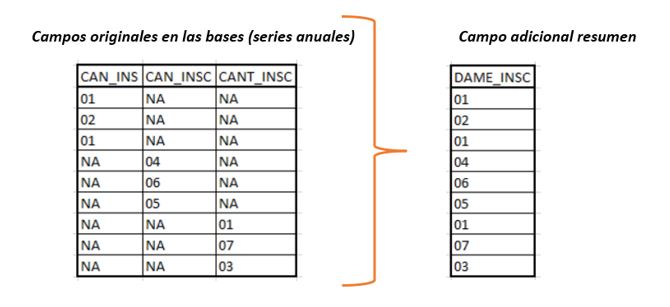
Como se logra apreciar en la tabla, existen 3 variables que representan el año de inscripción ANIO_INS, ANIO_INSC y ANO_INSC. Lo mismo ocurre con las variables geográficas correspondientes al Cantón de inscripción y nacimiento en los campos CAN_INS, CAN_INSC y CANT_INSC; CAN_NAC y CANT_NAC respectivamente.
Por estas situaciones de Ecuador y otros países también, es que el trabajo de armonización parte en la revisión y comparación del contendido de los campos, es decir, identificar las similitudes o diferencias entre los campos, en otras palabras, confirmar que se trate de la misma información captada. Confirmado ello, se procede a la creación de una variable adicional que tenga la conformación de la base, pero con un formato único.
Otro caso también identificado en este proceso, y que es relevante resaltar, es la existencia de diferencias de las etiquetas de las categorías de una misma variable entre las distintas bases. Estos casos son muy comunes, sobre todo para los formatos sav, que generalmente poseen las etiquetas en las variables. Un ejemplo es la variable “Asistencia durante el parto”, tal como se muestra en la siguiente imagen:

Las tablas nos muestran que, una vez realizado el proceso de identificación y verificación del contenido de las variables, a través de la documentación disponible, las mismas son equivalentes en cuanto a la medición, aunque ambas tienen distintas categorías/etiquetas; por lo cual, en estos casos es necesario crear una variable adicional, que tenga la información equivalente de las categorías/etiquetas más actuales (B), ajustando la otra variable a ella (recodificar A).
Al respecto de las bases en formato CSV o DBF, se aclara que son los formatos más complejos de trabajar, pues, al no poseer un diccionario donde se exponga las categorías con sus etiquetas asociadas, el proceso de armonización se apoya con la revisión de la documentación asociada a las series correspondientes, para comprender el contenido de cada variable de la base.
Finalmente, entendiendo a grandes rasgos los elementos más relevantes del proceso de sistematización y armonización que debe realizarse para los países, se explica a continuación los pasos detallados dentro de esta actividad:
Nombre de archivos
Primero, asignar nombres estandarizados para cada uno de los archivos, con la estructura codigopais_tipodedato_año, por ejemplo: GTM_NAC_1997, que correspondería a los microdatos de nacimientos de Guatemala del año 1997.
Nombre de campos
Segundo, y como fue mencionado anteriormente, es necesario hacer una revisión de las variables, con el fin de no duplicar o perder información al momento de unir las diferentes series anuales. Para esto, es preciso listar todos los campos existentes en la base y corroborar si existen similitudes en los nombres y contenidos de éstos, y paralelamente, revisar la documentación, si hubiere, de dichas bases para proceder a la armonización del conjunto de variables similares.
A continuación, la imagen siguiente muestra el caso ya mencionado de Ecuador, sobre la variable correspondiente a entidad geográfica: Cantón. Como se puede apreciar en la imagen, existen tres campos asociados al Cantón de Inscripción del nacimiento:

Identificadas las variables, corroborada la información, se procede entonces a crear una variable o campo adicional, en el cual se unirán los valores correspondientes, como se muestra a continuación:
Recodificaciones de variables: Ejemplo de variable Edad
La variable edad no suele traer diferencias en sus formatos; no obstante, un caso muy relevante a destacar, y que debe tener especial atención es el caso de las defunciones fetales, ya que, en ciertos países, con el fin de identificar las defunciones correspondientes a fetales, almacenan las edades codificadas. Por ejemplo, México utiliza una codificación especial de 4 dígitos, donde, si el primer dígito corresponde a un 1, la edad de fallecimiento se encuentra en horas, si es un 2, la edad se encuentra en días, si es un 3, la edad se encuentra en meses, y, por último, si es un 4, corresponde a edad en años; y los restantes 3 dígitos corresponden a la edad propiamente (otros 3 dígitos, ejemplo, 4031 es edad 31 años).
Para homologar este tipo de casos a las demás bases, donde la edad es en valores continuos, se debe crear un campo temporal (TEMP) utilizando la siguiente lógica: Asignar 0 para aquellas celdas que su primer dígito sea diferente a 4; es decir, asignar 0 a todas las celdas que comiencen con 1 que sería horas, 2 días y 3 meses. Seguidamente, se crea el campo final que tomará la siguiente lógica: Si TEMP es igual a 4, extraiga los 3 dígitos del campo edad original para obtener la edad en años continuos.
Etiquetas
Dependiendo del tipo de archivo, los pasos a seguir se diferencian en el uso o no de etiquetas. Para el caso de los archivos SPSS (*.sav), es necesario corroborar que cada una de las etiquetas asociadas a los valores sean las mismas para todas las series, y si no es así, se procede a crear un campo adicional con la información de la base, recodificando si corresponde, para tener las etiquetas de la versión más actual de las series.
Siguiendo el ejemplo presentado previamente, debemos homologar la Variable A con los valores contenidos en la Variable B, para esto, es de vital importancia contar con la colaboración de los expertos del área y/o los usuarios finales de la base consolidada para asignar los valores nuevos en base a la utilidad que tendrá la misma. Como podemos notar, cada variable debe ser analizada en base a sus características, es decir, si pueden ser agregadas o desagregadas en función del valor actual. En este caso, y debido a la generalidad de la Variable B, se crea un campo nuevo en el cual se hace una recodificación de la Variable A, y se homologa con la Variable B.
Para aquellos archivos que no tengan etiquetas, los mismos deben ser analizados con la documentación asociada, y al igual que el proceso anterior, se crea un campo adicional con una copia de la data recodificada, agregando entonces las etiquetas que correspondan.
Verificación de identificadores
Otro paso que se debe realizar es la revisión de la existencia en la base de datos o en el diccionario de los códigos identificadores de cada entidad, teniendo en cuenta dos aspectos:
- Si existen las variables individuales, es decir, un código separado para cada nivel geográfico y de tipo numérico, se deben crear las variables adicionales, que repliquen este código, pero con las características necesarias (tipo de campo y largo) que permitan asignarlas como identificador único de la entidad posteriormente en Redatam. Para ello, cada entidad debe tener un código numérico en formato texto, y como se deben homologar entre bases, se debe mantener el largo constante por lo cual se debe rellenar de 0 a la izquierda hasta alcanzar el largo del código más grande que se haya definido para esa entidad, como se muestra a continuación:
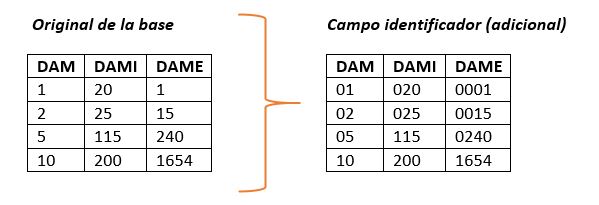
- Existen algunos casos en que la variable geográfica se encuentra creada por una concatenación de los códigos de las unidades geográficas menores en cada país, es decir, un solo campo que identifica DAM, DAMI y DAME. No obstante, por la estructura jerárquica planteada para la base Redatam, es necesario tener identificadores separados de las tres entidades, teniendo entonces que crear una variable o campo para cada uno, tal como se muestra en la imagen a continuación:
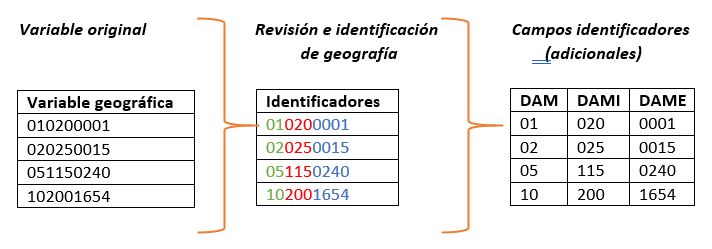
En este apartado hay un punto que tiene especial atención, y está referido a los identificadores de PAIS. Estas bases, al ser en sí de un país particular, no traen campos identificadores porque no son necesarios; no obstante; con mira a la consolidación de estas bases en una sola para la región, es importante aprovechar este proceso de armonización para agregar un campo identificador de país (ID_PAIS), el cual, como fue mencionado en otro apartado, corresponderá al código numérico de ISO 3166 de cada país, con el fin de mantener el estándar internacional de normalización.
Ordenamiento de datos
Realizados todos los pasos anteriores, se debe ordenar los datos para ser ingresados a Redatam. Es así como, una vez creados los campos identificadores, estos deben ser ordenados de manera ascendente siguiendo la jerarquía planteada, es decir ordenar por:
PAIS -> DAM -> DAMI (En caso de que corresponda)-> DAME -> ANBD -> NAC / DEF
Unión de bases por país
Teniendo las bases armonizadas, según todas las consideraciones antes mencionadas, se procede a unir las bases en un archivo único por país, siguiendo el orden de campos de la estructura Redatam y asignando un nombre estándar para todos los países, que lleva lo siguiente: codigopais_tipodedato_añoinicio_añofinal, por ejemplo, GTM_NAC_1997_2019.
Creación y Unión de bases en formato Redatam por país
Creación de bases de nacimientos y defunciones
Una vez ordenados los campos en las bases unidas, se procede a crear la base final por país, a través del módulo Create de Redatam. Para ello, al abrir el módulo Create, se construye la jerarquía previamente definida y se conecta a la base de origen (la armonizada), seleccionado la opción del formato de origen. Se agregan los identificadores en cada entidad, asignándolos como códigos de la entidad y, posteriormente, se agregan las variables a la entidad correspondiente, realizando los ajustes necesarios.

Este procedimiento se realiza para cada base disponible por país, es decir, se crea una base de nacimiento y una base de defunciones por país, que luego serán unidas en una sola base de hechos vitales por país.
Unión de bases por país
Una vez creadas las bases Redatam, de nacimientos, defunciones generales y defunciones fetales, ésta última, si hubiere información, mediante el módulo Admin de Redatam se genera la base consolidada por país extendiendo estas bases separadas.
Para ello, se abre el módulo Admin de Redatam y a través de la pestaña Herramientas (Tools), se pincha el botón Extender y se siguen los pasos del asistente, tal como se mostrará más adelante. Cabe señalar que Admin tiene distintas herramientas de gran utilidad para el manejo de las bases Redatam, pero para el presente, sólo prestaremos atención a la herramienta Extender, que en su concepto más básico lo que realiza es la extensión de una base de datos, es decir, agrega más información a una base primaria, siempre y cuando entre ambas bases exista una jerarquía común, y los códigos identificadores sean comparables entre sí.
Entonces, al ingresar al módulo, se debe ubicar el botón que se muestra en la imagen a continuación:

Una vez pinchado el botón, la primera solicitud del asistente es seleccionar la base principal, que corresponderá a la base madre y que será extendida. Para este caso es relevante identificar cual será la base para extender; y una vez definida la base principal, el asistente solicita la base secundaria que será la que aportará información a la primaria.
Como se ve en la imagen, se toma de ejemplo como base principal la base de nacimientos de Guatemala y secundaria la base de defunciones de Guatemala.
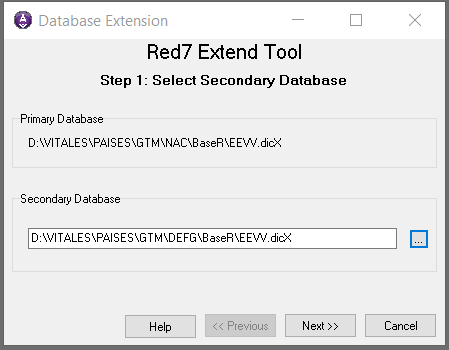
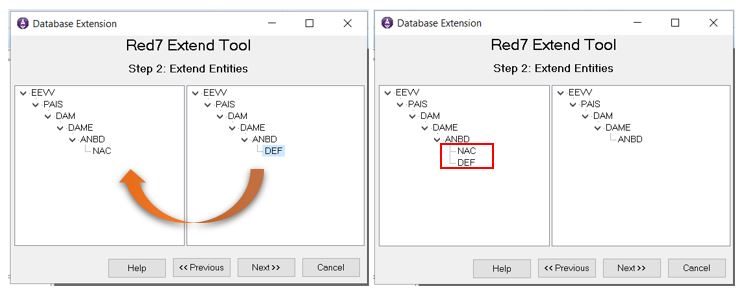
Seguidamente, para hacer el proceso de extensión, se debe arrastrar la entidad deseada (en el ejemplo DEF de Guatemala) hacia la entidad de su mismo nivel en la base de nacimientos (hasta la entidad ANBD) como muestran las imágenes a continuación:
Para finalizar el proceso de extensión, se deben seleccionar aquellas variables de la base secundaria que se deseen incorporar en la base primaria, que será al final, la base consolidada.
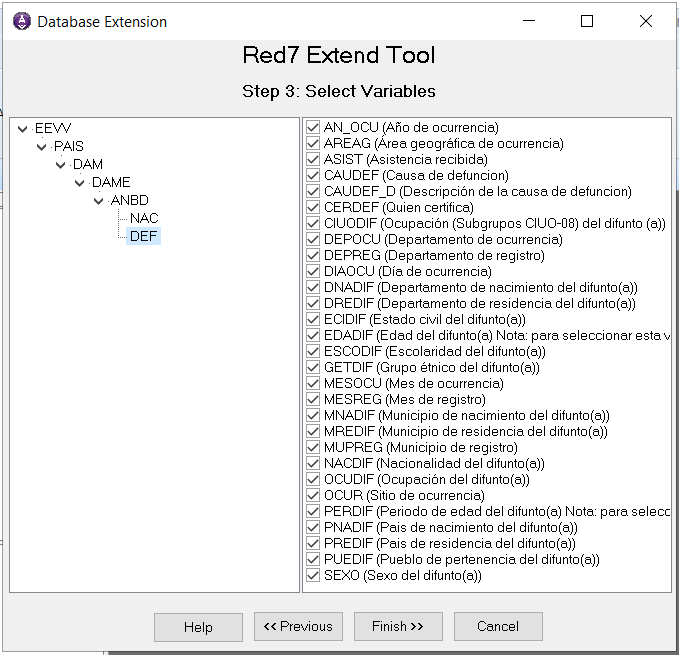
Una vez realizada la selección, al pinchar el botón Finish o Terminar, se realiza la extensión y se crea una nueva base consolidada de hechos vitales por país, que tiene una jerarquía común, pero con los datos de nacimientos y defunciones, que permitirá el manejo y procesamiento de la información en una sola base.
Conclusiones
Sin duda alguna, los registros administrativos de los hechos vitales son de suma importancia para los países, ya que permiten estimar y proyectar el crecimiento de las poblaciones, lo que, a su vez, permite planificar de mejor manera las políticas que impulsen el desarrollo de nuestros países.
Luego de este ejercicio, queda en evidencia la gran cantidad de diferencias que existe entre los archivos que almacenan la información de los hechos vitales, destacando incluso, diferencias entre el mismo país con el paso de los años.
Esta situación resalta la importancia de contar con estos lineamientos sobre procesos de armonización y homologación de archivos, que permitan obtener la consolidación de bases únicas, que almacenen bajo una estructura común, toda la información de hechos vitales.
No obstante, hay que resaltar que, estos pasos previos a llegar a tener una base homologada pueden simplificarse o reducirse si las instituciones encargadas de la generación del dato primario tienen un acuerdo mínimo de normalización, al menos en el diseño de sus bases de datos.
Es así como sobresale la utilidad de Redatam como un software completo, porque, si bien se debe realizar una serie de pasos y procesos previos en los archivos originales que serán la fuente para crear las bases en formato Redatam, éste permite, además de crear las bases individuales bajo un esquema común, que cabe destacar ya en sí es un avance para el fácil manejo y procesamiento de la información; permite también agregar a una base (extender), la información semejante, pudiendo contar al final, con un solo archivo que facilite y optimice el almacenamiento y el procesamiento de los datos.